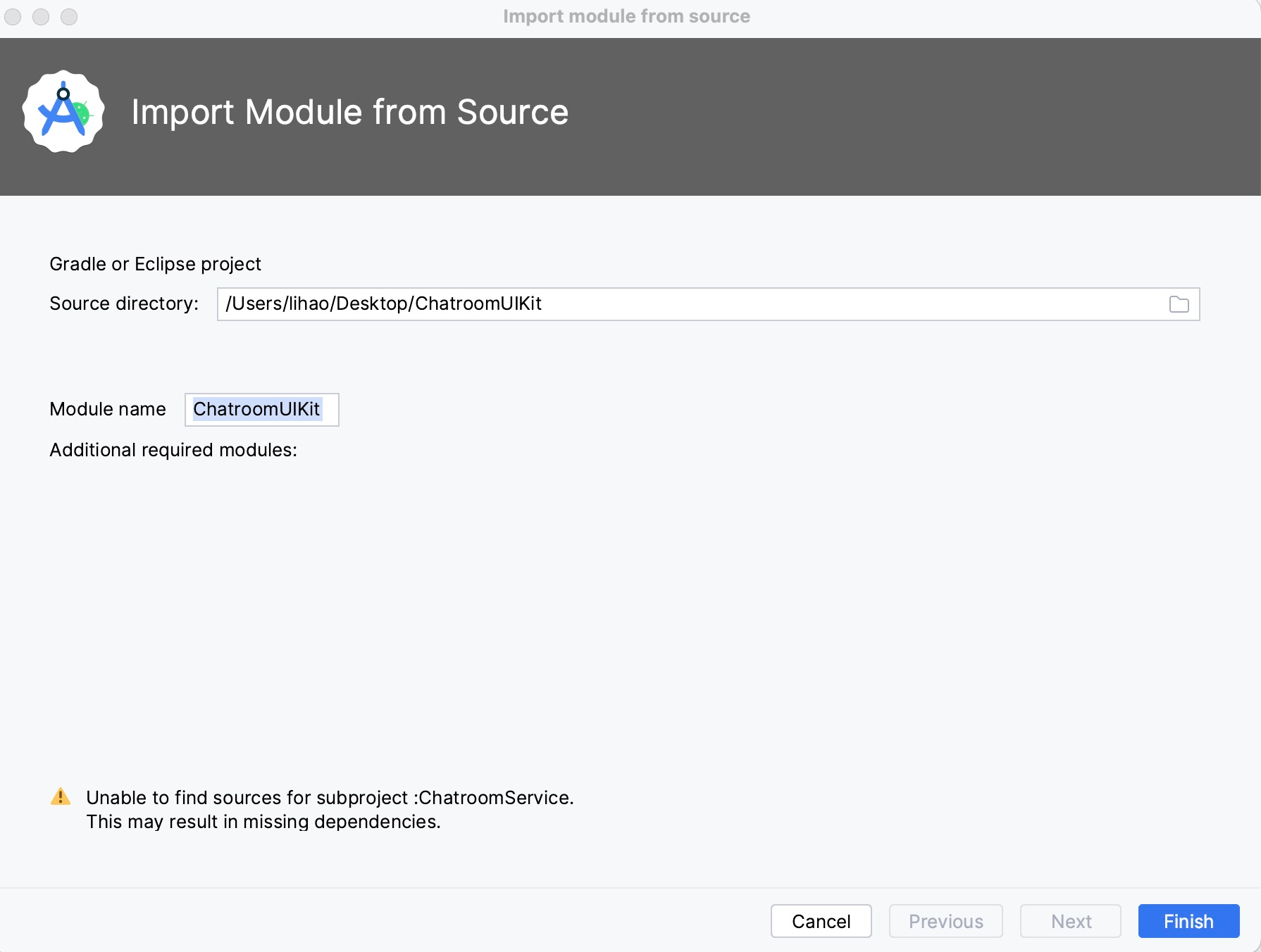
前言
平时我们做倒计时有很多种方法实现,也相对比较简单。但是最近碰到一个需求,需要在RecyclerView的item中实现倒计时,一般这种场景在电商的业务上应该也会有。那么我们就不能像开始单个倒计时一样简单做了,还需要考虑到viewholder的复用、性能等问题。
效果
这里可以简单先写个Demo看看效果

功能实现
1. 倒计时功能实现
核心就是开启一个计时器,每秒都更新时间到页面上,这个计时器的实现就很多了,比如直接handler,或者kotlin能用flow去做,或者TimerTask这些也能实现。打个广告,要做精准的倒计时可以看这篇文章juejin.cn/post/714065…
我这里是做Demo演示,为了代码整洁和方便,我就用TimerTask来做。
2. 设计思路
试着想想,你用RecyclerView做倒计时,每个ViewHolder的倒计时时间都不同,难道要在每个ViewHolder中开一个TimerTask来做吗?然后对viewholder的缓存再单独做处理?
我的想法是可以所有Item共用一个倒计时
这个系统有3个重要部分组成:
(1)倒计时的实现,只用一个TimerTask来做一个心跳的效果。每次心跳去更新正在显示的Item页面的倒计时 ,比如你有100个Item,但是显示在屏幕上的只有5个,那我只需要关心这5个Item的时间变动,其他95个没必要做处理。
(2)观察者队列。我的每次心跳都要通知正在显示的Item更新页面,那是不是很明显要通过观察者模式去做。
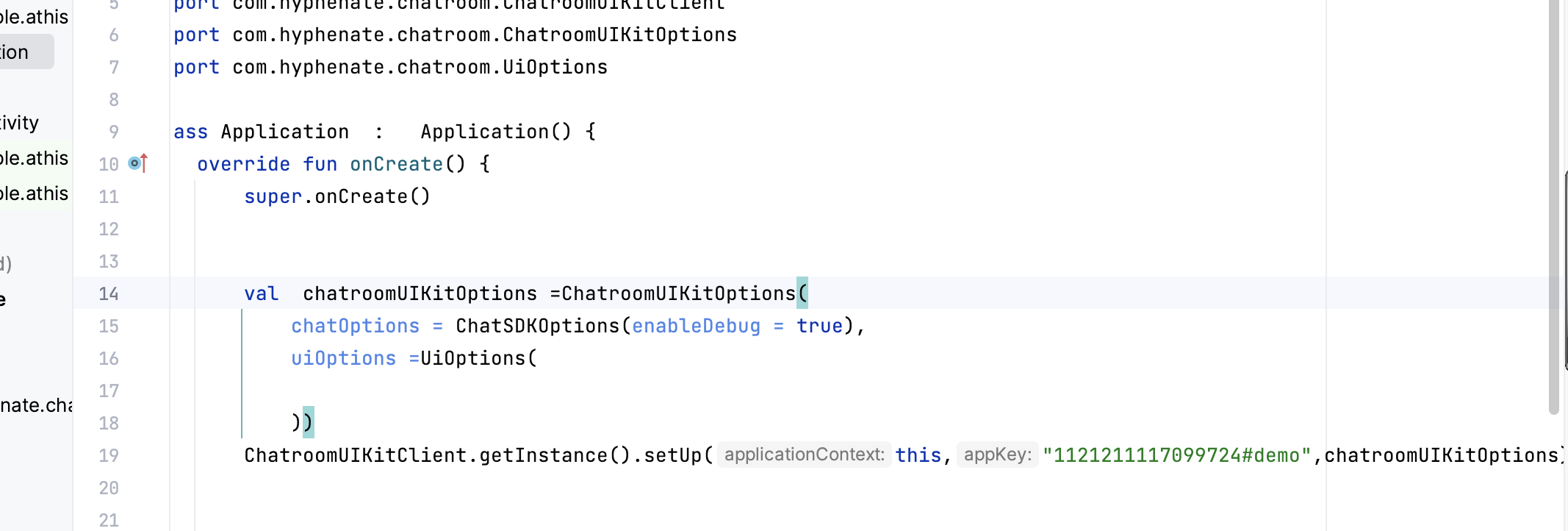
(3)倒计时时间列表。倒计时也需要用一个列表管理起来,recyclerview的页面显示是根据数据去显示,虽然比如说100个数组只需要5、6个viewholder来复用,但是你的差异数据还是100个数据。
3. 倒计时列表
倒计时列表的实现,我这里是用一个HashMap来实现,因为方便直接获取某个实际Item的当前倒计时的时间。
private val cdMap: HashMap<Long, Long> = HashMap()
我的key假设用一个id来做处理,因为我们的数据结构中基本都会存在id并且id是基础数据类型。
data class RcdItemData(
var id : Long, // id
var cd : Long // 总倒计时时间
)
添加倒计时
fun addCountDown(id: Long, totalCd: Long, isCover: Boolean = false) {
if (cdMap.containsKey(id)) {
if (isCover) {
cdMap[id] = totalCd
}
} else {
cdMap[id] = totalCd
}
}
这个isCover是一个策略,adapter数据刷新时是否更新倒计时,这里可以先不用管,可以简单看成
fun addCountDown(id: Long, totalCd: Long, isCover: Boolean = false) {
if (!cdMap.containsKey(id)) {
cdMap[id] = totalCd
}
}
清除倒计时(比如页面退出时就需要做释放操作)
fun clearCountDown() {
cdMap.clear()
}
获取某个Item当前倒计时的时间
fun getCountDownById(id: Long): Long? {
if (cdMap.containsKey(id)) {
return cdMap[id]
}
return null
}
更新时间(随心跳更新所有数据)
private fun updateCdByMap() {
cdMap.forEach { (t, u) ->
if (cdMap[t]!! > 0) {
cdMap[t] = u - 1
}
......
}
这些代码都不难理解,就不过多解释了
4. 观察者数组实现
先创建一个观察者数组
private var viewHolderObservables: ArrayList<OnItemSchedule?> = ArrayList()
然后就是最基础的添加观察者和移除观察者操作
fun addHolderObservable(onItemSchedule: OnItemSchedule?) {
viewHolderObservables.add(onItemSchedule)
}
fun removeHolderObservable(onItemSchedule: OnItemSchedule?) {
viewHolderObservables.remove(onItemSchedule)
}
fun releaseHolderObservable() {
viewHolderObservables.clear()
}
通知观察者(通知Item倒计时1秒了,可以刷新页面了)
private fun notifyCdFinish() {
viewHolderObservables.forEach {
it?.onCdSchedule()
}
}
5. 倒计时心跳实现
前面说了,我们让所有的Item共用一个倒计时,也是通过一个心跳去更新各自倒计时时间
private var task: TimerTask? = null
private var timer: Timer? = null
开始倒计时
fun startHeartBeat() {
if (task == null) {
timer = Timer()
task = object : TimerTask() {
override fun run() {
updateCdByMap()
}
}
timer?.schedule(task, 1000, 1000) // 每隔 1 秒钟执行一次
}
}
每一秒都会调用updateCdByMap()方法去刷新时间。
private fun updateCdByMap() {
cdMap.forEach { (t, u) ->
if (cdMap[t]!! > 0) {
cdMap[t] = u - 1
}
}
// 更改完数据之后通知观察者
Handler(Looper.getMainLooper()).post {
notifyCdFinish()
}
}
TimerTask会在子线程中进行,所以最后通知观察者的操作需要切到主线程
最后关闭倒计时(页面关闭这些时机调用)
fun closeHeartBeat() {
task?.cancel()
task = null
timer = null
}
6. 整体功能
因为上面是拆开来解释说明,这里再把整个工具的代码合起来可能会比较好管理。
object RecyclerCountDownManager {
private var task: TimerTask? = null
private var timer: Timer? = null
// viewHolder观察者
private var viewHolderObservables: ArrayList<OnItemSchedule?> = ArrayList()
// 倒计时对象数组
private val cdMap: HashMap<Long, Long> = HashMap()
/**
* 添加viewHolder观察
*/
fun addHolderObservable(onItemSchedule: OnItemSchedule?) {
viewHolderObservables.add(onItemSchedule)
}
fun removeHolderObservable(onItemSchedule: OnItemSchedule?) {
viewHolderObservables.remove(onItemSchedule)
}
fun releaseHolderObservable() {
viewHolderObservables.clear()
}
/**
* 添加倒计时对象
* @param totalCd 总倒计时时间
* @param isCover 是否覆盖
*/
fun addCountDown(id: Long, totalCd: Long, isCover: Boolean = false) {
if (cdMap.containsKey(id)) {
if (isCover) {
cdMap[id] = totalCd
}
} else {
cdMap[id] = totalCd
}
}
/**
* 清除倒计时
*/
fun clearCountDown() {
cdMap.clear()
}
/**
* 根据id获取倒计时
*/
fun getCountDownById(id: Long): Long? {
if (cdMap.containsKey(id)) {
return cdMap[id]
}
return null
}
/**
* 开始心跳
*/
fun startHeartBeat() {
if (task == null) {
timer = Timer()
task = object : TimerTask() {
override fun run() {
updateCdByMap()
}
}
timer?.schedule(task, 1000, 1000) // 每隔 1 秒钟执行一次
}
}
/**
* 更新所有倒计时对象
*/
private fun updateCdByMap() {
cdMap.forEach { (t, u) ->
if (cdMap[t]!! > 0) {
cdMap[t] = u - 1
}
}
// 更改完数据之后通知观察者
Handler(Looper.getMainLooper()).post {
notifyCdFinish()
}
}
private fun notifyCdFinish() {
viewHolderObservables.forEach {
it?.onCdSchedule()
}
}
/**
* 关闭心跳
*/
fun closeHeartBeat() {
task?.cancel()
task = null
timer = null
}
/**
* 调度通知,一般由ViewHolder实现该接口
*/
interface OnItemSchedule {
fun onCdSchedule()
}
}
可以看到代码都整体比较简单,就不用过多说明,就是需要注意一下这个是用一个单例去实现的工具,在页面关闭之后需要手动调用closeHeartBeat()、clearCountDown()、releaseHolderObservable()去释放资源。
调用的地方,Demo的Adapter
class RcdAdapter(var context: Context, var list: List<RcdItemData>) :
RecyclerView.Adapter<RcdAdapter.RcdViewHolder>() {
init {
// 因为模式默认选择不覆盖,需要每次添加前先清除
RecyclerCountDownManager.clearCountDown()
list.forEach {
RecyclerCountDownManager.addCountDown(it.id, it.cd)
}
}
override fun onCreateViewHolder(parent: ViewGr0up, viewType: Int): RcdViewHolder {
val text: TextView = TextView(context)
text.layoutParams = ViewGr0up.LayoutParams(ViewGr0up.LayoutParams.MATCH_PARENT, 64)
text.gravity = Gravity.CENTER
val holder = RcdViewHolder(text)
RecyclerCountDownManager.addHolderObservable(holder)
return holder
}
override fun getItemCount(): Int {
return list.size
}
override fun onBindViewHolder(holder: RcdViewHolder, position: Int) {
holder.setData(list[position])
}
class RcdViewHolder(var view: TextView) : RecyclerView.ViewHolder(view),
RecyclerCountDownManager.OnItemSchedule {
private var mData: RcdItemData? = null
fun setData(data: RcdItemData) {
mData = data
}
override fun onCdSchedule() {
val cd = mData?.id?.let { RecyclerCountDownManager.getCountDownById(it) }
if (cd != null) {
// 测试展示分秒
view.text = "${String.format("d", cd / 60)}:${String.format("d", cd % 60)}"
}
}
}
}
其他都比较基础的adapter的写法,就是viewholder要实现RecyclerCountDownManager.OnItemSchedule来充当观察者,然后拿到列表数据后调用RecyclerCountDownManager.addCountDown(it.id, it.cd)去创建倒计时列表。在onCreateViewHolder中调用RecyclerCountDownManager.addHolderObservable(holder)去添加观察者。最后在onCdSchedule()回调中做倒计时的更新

在页面销毁的时候主动释放内存































































































 若不是最近看到这样一篇新闻。
若不是最近看到这样一篇新闻。
 当时机哥身边的亲朋好友,只要是有智能手机的。
当时机哥身边的亲朋好友,只要是有智能手机的。
 原因倒是不复杂,在那个流量资费偏高的年代。
原因倒是不复杂,在那个流量资费偏高的年代。 WiFi万能钥匙,总是能如它的名字般神奇,帮用户成功连上WiFi。
WiFi万能钥匙,总是能如它的名字般神奇,帮用户成功连上WiFi。
 关键是,这软件还免费使用。
关键是,这软件还免费使用。
 WiFi万能钥匙发布不到三年,就拥有超过5亿的激活用户。
WiFi万能钥匙发布不到三年,就拥有超过5亿的激活用户。 什么叫风头无两啊,
什么叫风头无两啊,


 再加上App内部,出现了各种离谱的广告。
再加上App内部,出现了各种离谱的广告。 不知道的,还以为下了个病毒软件呢...
不知道的,还以为下了个病毒软件呢...
 但它这些年,积攒起来的崩坏口碑。
但它这些年,积攒起来的崩坏口碑。
 当然啦,如果只是广告讨人嫌。
当然啦,如果只是广告讨人嫌。
 但它能帮咱们连上各种场合的WiFi,原理并不是暴力破解。
但它能帮咱们连上各种场合的WiFi,原理并不是暴力破解。
 听起来,似乎是个不错的模式对吧。
听起来,似乎是个不错的模式对吧。 你帮我,我帮你,天下就没有难办的事儿了。
你帮我,我帮你,天下就没有难办的事儿了。
 但理想很丰满,现实很骨感。
但理想很丰满,现实很骨感。

 我凭什么无缘无故,给一个陌生人一块钱?
我凭什么无缘无故,给一个陌生人一块钱?
 他表示,App可以直接从用户手机拿到WiFi密码。
他表示,App可以直接从用户手机拿到WiFi密码。
 可谓是明文存放,点开就送。
可谓是明文存放,点开就送。
 可很凑巧的是,早期的安卓手机获取权限非常简单。
可很凑巧的是,早期的安卓手机获取权限非常简单。
 紧接着,最关键的问题来了。
紧接着,最关键的问题来了。
 作为一个,只会输入“Hello World”的代码废柴。
作为一个,只会输入“Hello World”的代码废柴。

 嗯?难道说...
嗯?难道说...
 如果实在遇到一些,数据库里配对不上的WiFi。
如果实在遇到一些,数据库里配对不上的WiFi。
 机友们都懂的,其实很多家庭路由器,密码都设置得很简单。
机友们都懂的,其实很多家庭路由器,密码都设置得很简单。


 “我们可是有9亿用户总量的,欢迎来合作啊喂。
“我们可是有9亿用户总量的,欢迎来合作啊喂。
 不能说克制,只能说处处皆是广告位。
不能说克制,只能说处处皆是广告位。
 而WiFi万能钥匙,对于广告的内容筛选,更是让人汗流浃背。
而WiFi万能钥匙,对于广告的内容筛选,更是让人汗流浃背。

 讲道理,以它如此庞大的用户总量。
讲道理,以它如此庞大的用户总量。 更何况,现在早就不是,流氓App能随意践踏手机的时代了。
更何况,现在早就不是,流氓App能随意践踏手机的时代了。


 结果发现,它现在往App塞了个短剧板块。
结果发现,它现在往App塞了个短剧板块。
 emmm...机哥也没啥好说的,祝它一切顺利吧。
emmm...机哥也没啥好说的,祝它一切顺利吧。