
深度优先搜索和广度优先搜索
不撞南墙不回头-深度优先搜索
基础部分
对于深度优先搜索和广度优先搜索,我很难形象的去表达它的定义。我们从一个例子来切入。
输入一个数字n,输出1~n的全排列。即n=3时,输出123,132,213,231,312,321
把问题形象化,假如有1,2,3三张扑克牌和编号为1,2,3的三个箱子,把三张扑克牌分别放到三个箱子里有几种方法?
我们用深度优先遍历搜索的思想来考虑这个问题。
到1号箱子面前时,我们手里有1,2,3三种牌,我们把1放进去,然后走到2号箱子面签,手里有2,3两张牌, 然后我们把2放进去,再走到3号箱子前,手里之后3这张牌,所以把3放进去,然后再往前走到我们想象出来的一个4号箱子前,我们手里没牌了,所以,前面三个箱子中放牌的组合就是要输出的一种组合方式。(123)
然后我们后退到3号箱子,把3这张拍取出来,因为这时我们手里只有一张牌,所以再往里放的话还是原来那种情况,所以我们还要再往后推,推到2号箱子前,把2从箱子中取出来,这时候我们手里有2,3两张牌,这时我们可以把3放进2号箱子,然后走到3号箱子中把2放进去,这又是一种要输出的组合方式.(132)
就找这个思路继续下去再次回退的时候,我们就要退到1号箱,取出1,然后分别放2和3进去,然后产生其余的组合方式。
有点啰嗦,但是基本是这么一个思路。
我们来看一下实现的代码
def sortNumber(self, n):
flag = [False for i in range(n)]
a = [0 for i in range(n)]
l = []
def dfs(step):
if step == n:
l.append(a[:])
return
for i in range(n):
if flag[i] is False:
flag[i] = True
a[step] = i
dfs(step + 1)
flag[i] = False
dfs(0)
return l输出是
[[0, 1, 2], [0, 2, 1], [1, 0, 2], [1, 2, 0], [2, 0, 1], [2, 1, 0]]我们创建的a这个list相当于上面说到的箱子,flag这个list呢,来标识某一个数字是否已经被用过了。
其实主要的思想就这dfs方法里面的这个for循环中,在依次的排序中,我们默认优先使用最小的那个数字,这个for循环其实就代表了一个位置上有机会放所有的这些数字,这个flag标识就避免了在一个位置重复使用数字的问题。
如果if 成立,说明当前位置可以使用这个数字,所以把这个数字放到a这个数组中,然后flag相同为的标识改为True,也就是说明这个数已经被占用了,然后在调用方法本身,进行下一步。
flag[i] = False这句代码是很重要的,在上面的dfs(也就是下一步)结束之后,返回到当前这个阶段,我们必须模拟收回这个数字,也就是把flag置位False,表示这个数字又可以用了。
思路大概就是这样子的,这就是深度优先搜索的一个简单的场景。用debug跟一下,一步一步的来看代码就更清晰的了。
迷宫问题
上面我们已经简单的了解了深度优先搜索,下面我们通过一个迷宫的问题来进一步数字这个算法,然后同时引出我们的广度优先搜索。
迷宫是由m行n列的单元格组成,每个单元格要不是空地,要不就是障碍物,我们的任务是找到一条从起点到终点的最短路径。
我们抽象成模型来看一下

start代表起点,end代表终点,x代表障碍物也就是不能通过的点。
首先我们来分析一下,从start(0,0)这个点,甚至说是每一个点出发,都有四个方向可以走,上下左右,仅对于(0,0)这个点来说,只能往右和下走,因为往左和上就到了单元格外面了,我们可以称之为越界了。
我们用深度优先的思想来考虑的话,我们可以从出发点开始,全部都先往一个方向走,然后走到遇到障碍物或者到了边界的情况下,在改变另一个方向,然后再走到底,这样一直走下去。
拿到我们这个题目中,我们可以这样来思考,在走的时候,我们规定一个右下左上这样的顺序,也就是先往右走,走到不能往右走的时候在变换方向。比如我们从(0,0)走到(0,1)这个点,在(0,1)这个点也是先往右走,但是我们发现(0,2)是障碍物,所以我们就改变为往下走,走到(1,1),然后在(1,1)开始也是先向右走,这样一直走下去,直到找到我们的目标点。
其中我们要注意一点,在右下左上这四个方向中有一个方向是我们来时候的方向,在当前这个点,四个方向没有走完之前我们不要后退到上一个点,所以我们也需要一个像前面排数字代码里面的flag数组来记录当前位置时候被占用。我们必须是四个方向都走完了才能往后退到上一个换方向。
下面我贴一下代码
def depthFirstSearch(self):
m = 5
n = 4
# 5行 4 列
flag = [[False for i in range(n)] for j in range(m)]
# 存储不能同行的位置
a = [[False for i in range(n)] for j in range(m)]
a[0][2] = True
a[2][2] = True
a[3][1] = True
a[4][3] = True
global min_step
min_step = 99999
director_l = [[0, 1], [1, 0], [0, -1], [-1, 0]]
def dfs(x, y, step):
# 什么情况下停止 (找到目标坐标)
if x == 3 and y == 2:
global min_step
if step < min_step:
min_step = step
return
# 右下左上
for i in range(4):
# 下一个点
nextX = x + director_l[i][0]
nextY = y + director_l[i][1]
# 是否越界
if nextX < 0 or nextX >= m or nextY < 0 or nextY >= n:
continue
# 不是障碍 and 改点还没有走过
if a[x][y] is False and flag[x][y] is False:
flag[x][y] = True
dfs(nextX, nextY, step+1)
flag[x][y] = False #回收
dfs(0, 0, 0)
return min_step首先flag这个算是二位数组吧,来记录我们位置是否占用了,然后a这个数组,是来记录整个单元格的,也就是标识那些障碍物的位置坐标。同样的,重点是这个dfs方法,他的参数x,y是指当前的坐标,step是步数。
这个大家可以看到一个director_l的数组,他是来辅助我们根据当前左边和不同方向计算下一个位置的坐标的。
dfs中我们已经注明了搜索停止的判断方式,也就是找到(3,2)这个点,然后下面的for循环,则代表四个不同的方向,每一个方向我们都会先求出他的位置,然后判断是否越界,如果没有越界在判断是否是障碍或者是否已经走过了,满足了所有的判断条件,我们在继续往下一个点,直到找到目标,比较路径的步数。
这就是深度优先搜索了,当然,这个题目我们还有别的解法,这就到了我们说的广度优先搜索。
层层递进-广度优先搜索
我们先大体说一下广度优先搜索的思路,深度优先是先穷尽一个方向,而广度优先呢,则是基于一个位置,先拿到他所有能到达的位置,然后分别基于这些新位置,拿到他们能到达的所有位置,一次这样层层的递进,直到找到我们的终点。
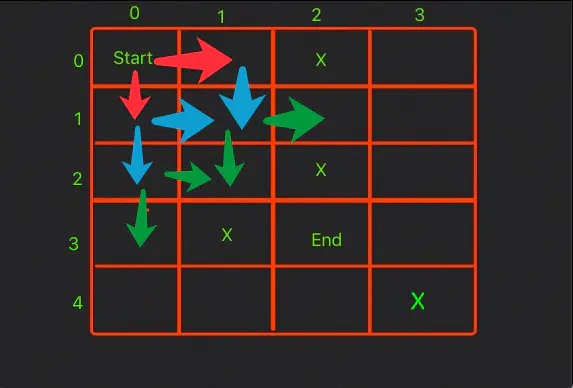
从(0,0)出发,可以到达(0,1)和(1,0),然后再从(0,1)出发到达(1,1),从(1,0)出发,到达(2,0)和(1,1),以此类推。
所以我们我们维护一个队列来储存每一层遍历到达的点,当然了,不要重复储存同一个点。我们用一个指针head来标识当前的基准位置,也就是说最开始指向(0,0),当储存完毕所有(0,0)能抵达的位置时,我们就应该改变我们的基准位置了,这时候head++,就到了(0,1)这个位置,然后储存完他能到的所有位置,head++,就到了(1,0),然后继续。
def breadthFirstSearch(self):
class Node:
def __init__(self):
x = 0
y = 0
step = 0
m, n = 5, 4
# 记录
flag = [[False for i in range(n)] for j in range(m)]
# 储存地图信息
a = [[False for i in range(n)] for j in range(m)]
a[0][2] = True
a[2][2] = True
a[3][1] = True
a[4][3] = True
# 队列
l = []
startX, startY, step = 0, 0, 0
head = 0
index = 0
node = Node()
node.x = startX
node.y = startY
node.step = step
index += 1
l.append(node)
flag[0][0] = True
director_l = [[0, 1], [1, 0], [0, -1], [-1, 0]]
while head < index:
last_node = l[head]
# 处理四个方向
for i in range(4):
# 当前位置
currentX = last_node.x + director_l[i][0]
currentY = last_node.y + director_l[i][1]
# 找到目标
if currentX == 4 and currentY == 2:
print('step = ' + str(last_node.step + 1))
return
#是否越界
if currentX < 0 or currentY < 0 or currentX >= m or currentY >= n:
continue
if a[currentX][currentY] is False and flag[currentX][currentY] is False:
#不是目标
flag[currentX][currentY] = True
node_new = Node()
node_new.x = currentX
node_new.y = currentY
node_new.step = last_node.step+1
l.append(node_new)
index += 1
head += 1首先我们定义了一个节点Node的类,来封装节点位置和当前的步数,flag,a,director_l这两个数组作用跟深度优先搜索相同,l是我们维护的队列,head指针指向当前基准的那个位置的,index指针指向队列尾。首先我们先把第一个Node(也就是起点)存进队列,广度优先搜索不需要递归,只要加一个循环就行。
每次走到符合要求的位置,我们便把他封装成Node来存进对列中,每存一个index都要+1.
head指针必须在一个节点四个方向都处理完了之后才可以+1,变换下一个基准节点。
小结
简单的介绍了深度优先搜索和广度优先搜索,深度优先有一种先穷尽一个方向然后结合使用回溯来找到解,广度呢,可能就是每做一次操作就涵盖了所有的可能结果,然后一步步往后推出去,找到最后的解。这算我个人的理解吧,不准确也不官方,思想也只能算是稍有体会,还得继续努力。
题外话
碍于自己的算法基础太差,最近一直在做算法题,我是先刷了一段时间的题目,发现吃力了,才开始看的书。感觉有点本末倒置。其实应该是先看看书,把算法的一些常用大类搞清楚了,形成一个知识框架,这样在遇到问题的时候可以知道往那些方向上面思考,可能会好一些吧。
链接:https://www.jianshu.com/p/9a6a65078fc2
