
在SFU上实现RED音频冗余功能
最近,Chrome添加了使用RFC 2198中定义的RED格式给音频流添加冗余的选项。Fippo之前写过一篇文章解释该过程和实现,建议大家研读。大致总结一下这篇文章的话,主要讲述了RED的工作原理是在同一个数据包中添加具有不同时间戳的冗余有效载荷。如果你在出现损耗的网络中丢失了一个数据包,若另一个数据包被成功接收,其中可能会含有丢失的数据,产生更好的音频质量。
上述假设发生在简化的一对一场景下,但音频质量问题往往对多方大型通话影响最大。本篇作为Fippo文章的后续,Jitsi 设计师、 Improving Scale and Media Quality with Cascading SFU 的作者Boris Grozev会在本文中向我们介绍他为应对在更复杂的环境添加音频冗余而进行的设计和测试,该环境中存在大量端通过SFU路由媒体。

Fippo在之前的文章中介绍了如何无需任何类似SFU的中间件,就能在标准的端对端呼叫中添加冗余数据包。那么当你在中间件插入SFU时会发生什么呢?需要考虑以下问题:
- 如何处理会议中不同客户有不同RED功能的情况?可能会议中只有一部分人支持RED。事实上该情况现在很常见,因为RED是WebRTC、Chromium、Chrome中相对较新添加的功能。
- 哪些流应该添加冗余?我们是否应该给所有音频流添加冗余,即便这样会产生额外成本?还是只为当前活动的扬声器(或2-3个扬声器)添加冗余?
- 哪些部分应该添加冗余?在多SFU级联场景中,我们是否需要为SFU-SFU流添加冗余?
接下来我们会深入讨论这些问题,介绍我们最近在Jitsi Videobridge中的实现内容,并分享更多测试结果。
RED 客户端和非RED 客户端的混搭
如果会议所有客户端都支持RED,他们便无需在服务器上进行任何特殊处理,即可使用它,SFU还是像往常一样转发音频流,只不过恰好包含冗余罢了。然而,如果会议中一些客户端支持RED,一些客户端不支持RED,这就有点复杂了。基于发送方和/或接收方是否支持RED,我们需要考虑以下四种情况:
非RED到非RED
RED到RED
非RED到RED
RED到非RED
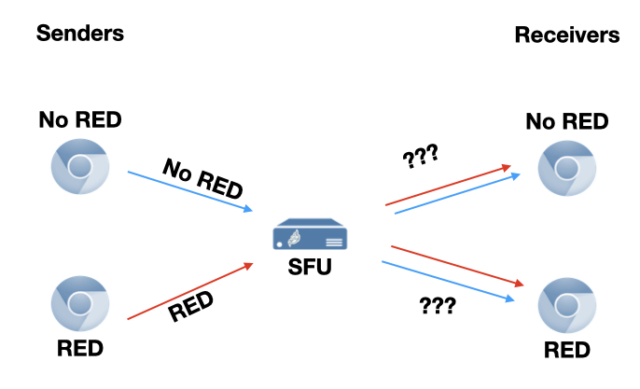
非RED 到非RED
第一种情况比较简单:从一个非RED客户端将流转发到一个非RED客户端。流上没有冗余,我们也不被允许添加任何冗余。没什么好办法能改善该情况了。
RED 到RED
第二种也很简单:将RED流转发到支持RED的客户端。最简单的做法就是简单转发不变的转发流,这也是一个合理的解决方案。因为不必要对RED流重新编码,我们只需将其转发过去即可。
非RED 到RED
SFU的最后一种情况是将Opus流转发到支持RED的客户端,即对RED进行编码,也就是Fippo文章中所说的一对一情况,但增加了一些下述的限制。
RED 到非RED
第三种是比较困难的情况,即将RED流转发到没有RED的客户端。当然,我们可以直接删除RED并丢弃冗余,但如果SFU和客户端之间丢包,这也不能提高音频质量。该缺陷揭示了RFC2198 RED格式的一个限制。因为中间件SFU需要产生有效的RTP数据流,它需要知道从冗余块中恢复的数据包应该使用哪个RTP序列号,但该信息并不包含在RED header里。这是因为该格式被设计为由端点,而不是由时间戳足以用于回放的中间件来解释,所以其中只包含了一个 “时间戳偏移”(TO)字段。
0 1 2 3
0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
|F| block PT | timestamp offset | block length |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+如果我们总是使用distance 1,也就是总有一个冗余的数据包(详见Fippo有关distance的文章),对SFU来说不成问题。因为所有的RED包都有一个冗余块,其序列号就是RED包的序列号前面的那一串。同样,如果我们总是使用distance 2(两个冗余数据包),并为所有数据包添加冗余,是不会产生问题的。如果流采用为数据包特设添加冗余的distance 2,且该数据包包含语音活动时(即VAD位被设置),问题就来了。
(对于RED ) VAD 无益
假设原始流有三个数据包(seq=1,2,3)。其中一个包含语音,另外两个不包(没有VAD)。当RED编码器处理数据包3时,它只对数据包1添加冗余,因为数据包2不包含语音。
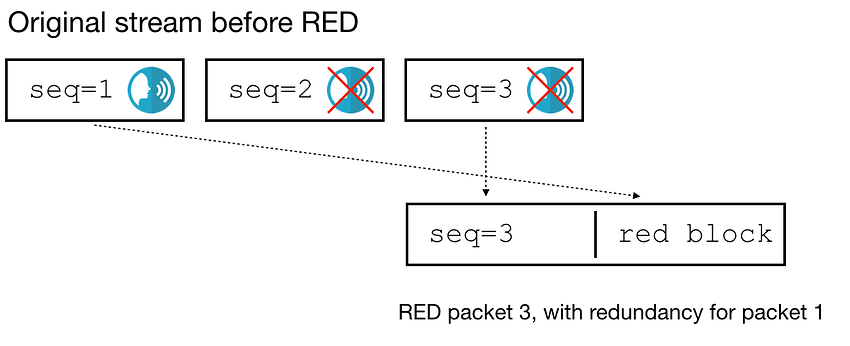
问题是:当我们在SFU上收到这样一个数据包时,我们怎么知道RED块是否包含数据包1或数据包2的副本呢?如果编码器使用的是distance 1,或者数据包1和2中的语音标志不见了,RED数据包看起来是一样的,其实包含了数据包2的冗余。
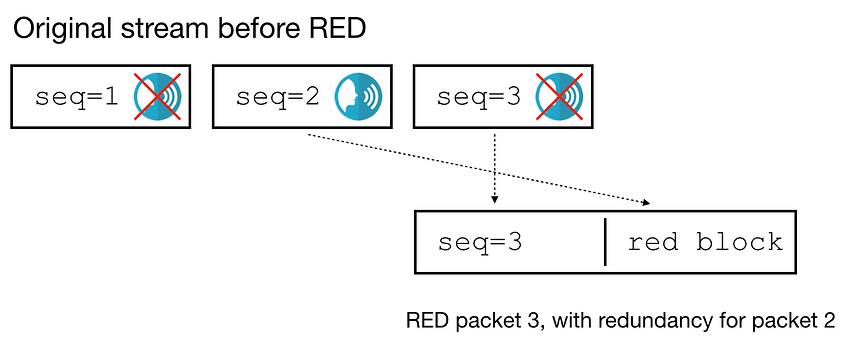
当我们从SFU的RED数据包中提取冗余时,要如何决定对它使用什么序列号呢?一种方法是看时间戳,对数据包的持续时间做出假设。由于我们使用Opus的RTP时钟速率为48000,帧数为20毫秒,即可表示为red_seq = seq – timestamp_offset * (20 / 48000) 。这样做出的假设就很多了。我们也可以更进一步,读取Opus数据包的持续时间。所以我们不必假设它是20毫秒,但也要考虑到如下问题:
它不能用于e2e加密流。
它是编解码器专用的。
技术上来说,opus流可以在中途改变帧大小。
改变RED
我们无法在当前的规范中找到一个好的解决方案。所以我们给RED编码器序列计数器增加了一个新的限制,以确保冗余数据包的序列号总是直接在主数据包的序列号之前。对于上面的示例流,RED编码器有三个有效选项。
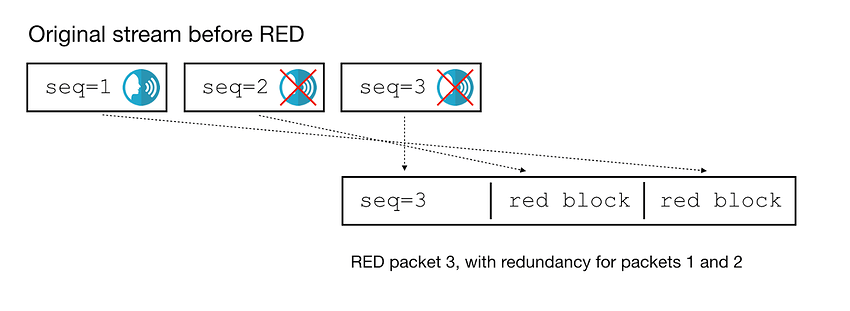
第一张图中的选项操作已被禁止了,即给数据包1添加冗余,但不给数据包2添加。这就是Fippo最新的WebRTC源补丁所实现的功能。
所有的流都应该有冗余吗?
在一对一的情况下,若双方也使用视频,那么相对于组合比特率来说RED的开支很小。对于一个典型的32kbps Opus流,distance 2的RED增加约64kbps的成本。而在我们的服务中,一典型的视频流所占成本为2Mbps,所以总体增加的开销在3%左右——并非微不足道,而是相对较小。
然而在多方会议中,若SFU向每个接收端转发多个流,且许多视频流是低比特率(即缩略图)运行时,增加的成本可能会更多。
我们从最简单的技术方案开始进行实现,即为所有流添加冗余,并假设大多数会议同时有多人发言。因为SFU不会转发标记为静音的音频,所以同时发言的人少意味着音频流少。因此在大多数情况下,每个与会者只会在少数音频流上收到RED,减少了开销 。事实上,根据我们从meet.jit.si得到的数据来看,78%的实时会议的发言人为三人及以下(即音频水平不为零的流),所以大多数情况下,在接收端点没有太多RED过载的可能性。
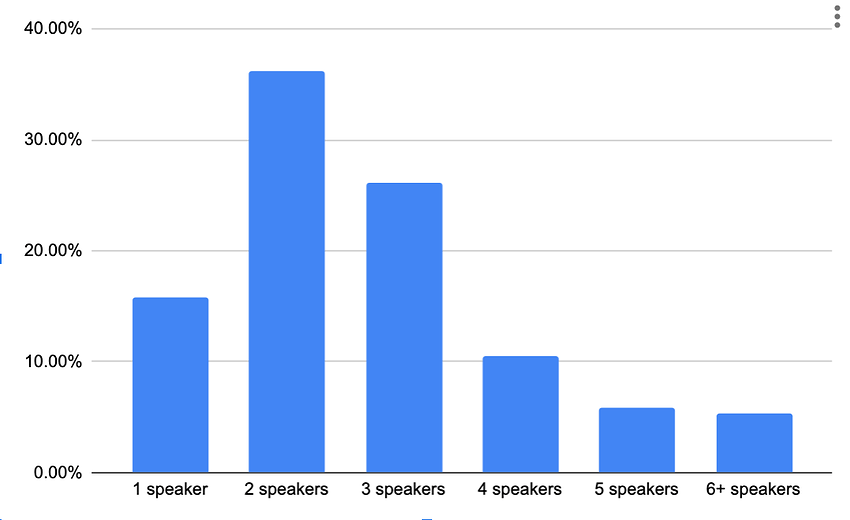
我们还可以做些什么来进一步减少开销呢?我们可以只为活跃的发言人,或者最活跃的2-3个发言人添加冗余。此外,我们还可以根据可用带宽和会议中的视频流做出更具体、复杂的决定。
级联式SFU
另外要考虑的是如何处理级联SFU中的RED。在这种情况下,我们用SFU到SFU的连接以获取更大规模。我们部署了稳定的高带宽链路,以及在SFU之间没有明显的数据包丢失,所以我们选择不主动给没有冗余的流添加冗余。但是我们也不会主动删除冗余,因为我们有很多低成本的带宽。最终的流程如下图所示:

测试结果
为了验证新的RED功能,我们创建了一个测试床以测量系统在不同的丢包情况下的表现。我们的默认配置是将SFU上编码的流设置为distance=2,vad-only=true。并且我们给以下两条链路都引入了20%、40%和60%的均匀丢包情况,即发送方和SFU之间大的链路(1.)和SFU和接收方之间的链路(2.)。数据包丢失的位置不同并不会造成大的影响。点击下方你可以收听发送端丢失的例子,所有的测试案例请点击此处收听。

注:请访问原文地址(见文章末尾处),播放音频示例。
通过收听例子,我们会发现因为RED的存在,音频质量有了明显提升。
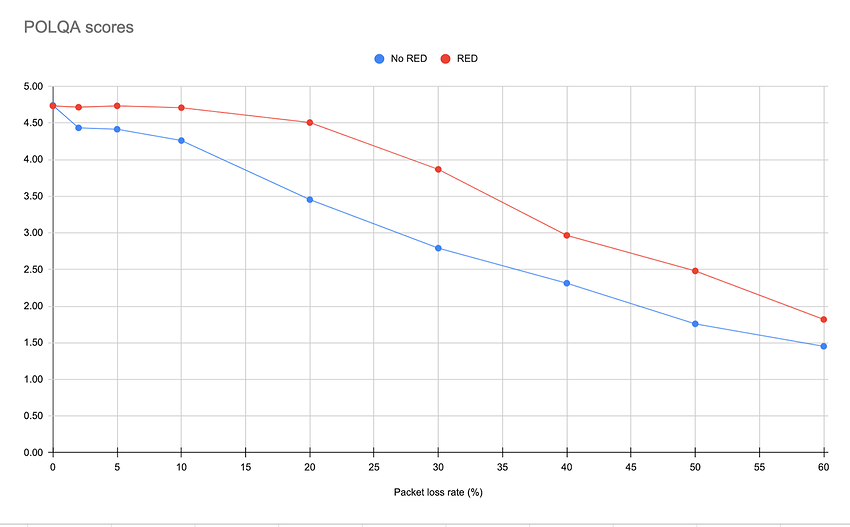
POLQA 测试
在另一个具有类似设置的实验中,我在8×8的同事Garth Judge使用POLQA标准和工具集量化了RED带来的影响。以下是他的检测结果。
结论
最近,使用RED标准的WebRTC音频冗余在Chrome浏览器进行了现场试验,试验显示该技术巨大的前景。要在多方会议环境中有效使用RED,就需要SFU上额外的服务器支持。我们的测试表明,这些SFU对RED的增强产生了切实效果。
但我们还有更多工作要做,包括选择要添加冗余的流的子集、使用VAD选择要添加的数据包,以及可能使用Opus LBRR(低比特率冗余)来降低冗余带来的额外比特率等等。
实验室的测试也表明,重度丢包下的音频质量得到了显著改善。请大家继续关注现场测试结果。
转自:https://www.agora.io/cn/community/blog/121-category/21120
