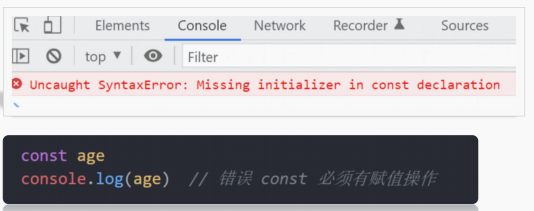
效果演示

不仅仅是实现效果,要封装,就封装好
看完了演示的效果,你是否在思考,代码应该怎么实现?先不着急写代码,先想想哪些地方是要可以动态配置的。首先第一个,进度条的形状是不是要可以换?然后进度条的背景色和填充的颜色,以及动画的时长是不是也要可以配置?没错,起始位置是不是也要可以换?最好还要让速度可以一会快一会慢对吧,画笔的笔帽是不是还可以选择平的或圆的?带着这些问题,我们再开始写代码。
代码实现
我们写一个自定义View,把可以动态配置的地方想好后,就可以定义自定义属性了。
<?xml version="1.0" encoding="utf-8"?>
<resources>
<declare-styleable name="DoraProgressView">
<attr name="dview_progressType">
<enum name="line" value="0"/>
<enum name="semicircle" value="1"/>
<enum name="semicircleReverse" value="2"/>
<enum name="circle" value="3"/>
<enum name="circleReverse" value="4"/>
</attr>
<attr name="dview_progressOrigin">
<enum name="left" value="0"/>
<enum name="top" value="1"/>
<enum name="right" value="2"/>
<enum name="bottom" value="3"/>
</attr>
<attr format="dimension|reference" name="dview_progressWidth"/>
<attr format="color|reference" name="dview_progressBgColor"/>
<attr format="color|reference" name="dview_progressHoverColor"/>
<attr format="integer" name="dview_animationTime"/>
<attr name="dview_paintCap">
<enum name="flat" value="0"/>
<enum name="round" value="1"/>
</attr>
</declare-styleable>
</resources>
然后我们不管三七二十一,先把自定义属性解析出来。
private fun initAttrs(context: Context, attrs: AttributeSet?, defStyleAttr: Int) {
val a = context.obtainStyledAttributes(
attrs,
R.styleable.DoraProgressView,
defStyleAttr,
0
)
when (a.getInt(R.styleable.DoraProgressView_dview_progressType, PROGRESS_TYPE_LINE)) {
0 -> progressType = PROGRESS_TYPE_LINE
1 -> progressType = PROGRESS_TYPE_SEMICIRCLE
2 -> progressType = PROGRESS_TYPE_SEMICIRCLE_REVERSE
3 -> progressType = PROGRESS_TYPE_CIRCLE
4 -> progressType = PROGRESS_TYPE_CIRCLE_REVERSE
}
when (a.getInt(R.styleable.DoraProgressView_dview_progressOrigin, PROGRESS_ORIGIN_LEFT)) {
0 -> progressOrigin = PROGRESS_ORIGIN_LEFT
1 -> progressOrigin = PROGRESS_ORIGIN_TOP
2 -> progressOrigin = PROGRESS_ORIGIN_RIGHT
3 -> progressOrigin = PROGRESS_ORIGIN_BOTTOM
}
when(a.getInt(R.styleable.DoraProgressView_dview_paintCap, 0)) {
0 -> paintCap = Paint.Cap.SQUARE
1 -> paintCap = Paint.Cap.ROUND
}
progressWidth = a.getDimension(R.styleable.DoraProgressView_dview_progressWidth, 30f)
progressBgColor =
a.getColor(R.styleable.DoraProgressView_dview_progressBgColor, Color.GRAY)
progressHoverColor =
a.getColor(R.styleable.DoraProgressView_dview_progressHoverColor, Color.BLUE)
animationTime = a.getInt(R.styleable.DoraProgressView_dview_animationTime, 1000)
a.recycle()
}
解析完自定义属性,切勿忘了释放TypedArray。接下来我们考虑下一步,测量。半圆是不是不要那么大的画板对吧,我们在测量的时候就要充分考虑进去。
override fun onMeasure(widthMeasureSpec: Int, heightMeasureSpec: Int) {
super.onMeasure(widthMeasureSpec, heightMeasureSpec)
progressBgPaint.strokeWidth = progressWidth
progressHoverPaint.strokeWidth = progressWidth
if (progressType == PROGRESS_TYPE_LINE) {
var left = 0f
var top = 0f
var right = measuredWidth.toFloat()
var bottom = measuredHeight.toFloat()
val isHorizontal = when(progressOrigin) {
PROGRESS_ORIGIN_LEFT, PROGRESS_ORIGIN_RIGHT -> true
else -> false
}
if (isHorizontal) {
top = (measuredHeight - progressWidth) / 2
bottom = (measuredHeight + progressWidth) / 2
progressBgRect[left + progressWidth / 2, top, right - progressWidth / 2] = bottom
} else {
left = (measuredWidth - progressWidth) / 2
right = (measuredWidth + progressWidth) / 2
progressBgRect[left, top + progressWidth / 2, right] = bottom - progressWidth / 2
}
} else if (progressType == PROGRESS_TYPE_CIRCLE || progressType == PROGRESS_TYPE_CIRCLE_REVERSE) {
var left = 0f
val top = 0f
var right = measuredWidth
var bottom = measuredHeight
progressBgRect[left + progressWidth / 2, top + progressWidth / 2, right - progressWidth / 2] =
bottom - progressWidth / 2
} else {
val isHorizontal = when(progressOrigin) {
PROGRESS_ORIGIN_LEFT, PROGRESS_ORIGIN_RIGHT -> true
else -> false
}
val min = measuredWidth.coerceAtMost(measuredHeight)
var left = 0f
var top = 0f
var right = 0f
var bottom = 0f
if (isHorizontal) {
if (measuredWidth >= min) {
left = ((measuredWidth - min) / 2).toFloat()
right = left + min
}
if (measuredHeight >= min) {
bottom = top + min
}
progressBgRect[left + progressWidth / 2, top + progressWidth / 2, right - progressWidth / 2] =
bottom - progressWidth / 2
setMeasuredDimension(
MeasureSpec.makeMeasureSpec(
(right - left).toInt(),
MeasureSpec.EXACTLY
),
MeasureSpec.makeMeasureSpec(
(bottom - top + progressWidth).toInt() / 2,
MeasureSpec.EXACTLY
)
)
} else {
if (measuredWidth >= min) {
right = left + min
}
if (measuredHeight >= min) {
top = ((measuredHeight - min) / 2).toFloat()
bottom = top + min
}
progressBgRect[left + progressWidth / 2, top + progressWidth / 2, right - progressWidth / 2] =
bottom - progressWidth / 2
setMeasuredDimension(
MeasureSpec.makeMeasureSpec(
(right - left + progressWidth).toInt() / 2,
MeasureSpec.EXACTLY
),
MeasureSpec.makeMeasureSpec(
(bottom - top).toInt(),
MeasureSpec.EXACTLY
)
)
}
}
}
View的onMeasure()方法是不是默认调用了一个
super.onMeasure(widthMeasureSpec, heightMeasureSpec)
它最终会调用setMeasuredDimension()方法来确定最终测量的结果吧。如果我们对默认的测量不满意,我们可以自己改,最后也调用setMeasuredDimension()方法把测量结果确认。半圆,如果是水平的情况下,我们的宽度就只要一半,相反如果是垂直的半圆,我们高度就只要一半。最后我们画还是照常画,只不过在最后把画到外面的部分移动到画板上显示出来。接下来就是我们最重要的绘图环节了。
override fun onDraw(canvas: Canvas) {
if (progressType == PROGRESS_TYPE_LINE) {
val isHorizontal = when(progressOrigin) {
PROGRESS_ORIGIN_LEFT, PROGRESS_ORIGIN_RIGHT -> true
else -> false
}
if (isHorizontal) {
canvas.drawLine(
progressBgRect.left,
measuredHeight / 2f,
progressBgRect.right,
measuredHeight / 2f,
progressBgPaint)
} else {
canvas.drawLine(measuredWidth / 2f,
progressBgRect.top,
measuredWidth / 2f,
progressBgRect.bottom, progressBgPaint)
}
if (percentRate > 0) {
when (progressOrigin) {
PROGRESS_ORIGIN_LEFT -> {
canvas.drawLine(
progressBgRect.left,
measuredHeight / 2f,
(progressBgRect.right) * percentRate,
measuredHeight / 2f,
progressHoverPaint
)
}
PROGRESS_ORIGIN_TOP -> {
canvas.drawLine(measuredWidth / 2f,
progressBgRect.top,
measuredWidth / 2f,
(progressBgRect.bottom) * percentRate,
progressHoverPaint)
}
PROGRESS_ORIGIN_RIGHT -> {
canvas.drawLine(
progressWidth / 2 + (progressBgRect.right) * (1 - percentRate),
measuredHeight / 2f,
progressBgRect.right,
measuredHeight / 2f,
progressHoverPaint
)
}
PROGRESS_ORIGIN_BOTTOM -> {
canvas.drawLine(measuredWidth / 2f,
progressWidth / 2 + (progressBgRect.bottom) * (1 - percentRate),
measuredWidth / 2f,
progressBgRect.bottom,
progressHoverPaint)
}
}
}
} else if (progressType == PROGRESS_TYPE_SEMICIRCLE) {
if (progressOrigin == PROGRESS_ORIGIN_LEFT) {
canvas.drawArc(progressBgRect, 180f, 180f, false, progressBgPaint)
canvas.drawArc(
progressBgRect,
180f,
angle.toFloat(),
false,
progressHoverPaint
)
} else if (progressOrigin == PROGRESS_ORIGIN_TOP) {
canvas.translate(-progressBgRect.width() / 2, 0f)
canvas.drawArc(progressBgRect, 270f, 180f, false, progressBgPaint)
canvas.drawArc(
progressBgRect,
270f,
angle.toFloat(),
false,
progressHoverPaint
)
} else if (progressOrigin == PROGRESS_ORIGIN_RIGHT) {
canvas.translate(0f, -progressBgRect.height() / 2)
canvas.drawArc(progressBgRect, 0f, 180f, false, progressBgPaint)
canvas.drawArc(
progressBgRect,
0f,
angle.toFloat(),
false,
progressHoverPaint
)
} else if (progressOrigin == PROGRESS_ORIGIN_BOTTOM) {
canvas.drawArc(progressBgRect, 90f, 180f, false, progressBgPaint)
canvas.drawArc(
progressBgRect,
90f,
angle.toFloat(),
false,
progressHoverPaint
)
}
} else if (progressType == PROGRESS_TYPE_SEMICIRCLE_REVERSE) {
if (progressOrigin == PROGRESS_ORIGIN_LEFT) {
canvas.translate(0f, -progressBgRect.height() / 2)
canvas.drawArc(progressBgRect, 180f, -180f, false, progressBgPaint)
canvas.drawArc(
progressBgRect,
180f,
-angle.toFloat(),
false,
progressHoverPaint
)
} else if (progressOrigin == PROGRESS_ORIGIN_TOP) {
canvas.drawArc(progressBgRect, 270f, -180f, false, progressBgPaint)
canvas.drawArc(
progressBgRect,
270f,
-angle.toFloat(),
false,
progressHoverPaint
)
} else if (progressOrigin == PROGRESS_ORIGIN_RIGHT) {
canvas.drawArc(progressBgRect, 0f, -180f, false, progressBgPaint)
canvas.drawArc(
progressBgRect,
0f,
-angle.toFloat(),
false,
progressHoverPaint
)
} else if (progressOrigin == PROGRESS_ORIGIN_BOTTOM) {
canvas.translate(-progressBgRect.width() / 2, 0f)
canvas.drawArc(progressBgRect, 90f, -180f, false, progressBgPaint)
canvas.drawArc(
progressBgRect,
90f,
-angle.toFloat(),
false,
progressHoverPaint
)
}
} else if (progressType == PROGRESS_TYPE_CIRCLE) {
val deltaAngle = if (progressOrigin == PROGRESS_ORIGIN_TOP) {
90f
} else if (progressOrigin == PROGRESS_ORIGIN_RIGHT) {
180f
} else if (progressOrigin == PROGRESS_ORIGIN_BOTTOM) {
270f
} else {
0f
}
canvas.drawArc(progressBgRect, 0f, 360f, false, progressBgPaint)
canvas.drawArc(
progressBgRect,
180f + deltaAngle,
angle.toFloat(),
false,
progressHoverPaint
)
} else if (progressType == PROGRESS_TYPE_CIRCLE_REVERSE) {
val deltaAngle = if (progressOrigin == PROGRESS_ORIGIN_TOP) {
90f
} else if (progressOrigin == PROGRESS_ORIGIN_RIGHT) {
180f
} else if (progressOrigin == PROGRESS_ORIGIN_BOTTOM) {
270f
} else {
0f
}
canvas.drawArc(progressBgRect, 0f, 360f, false, progressBgPaint)
canvas.drawArc(
progressBgRect,
180f + deltaAngle,
-angle.toFloat(),
false,
progressHoverPaint
)
}
}
绘图除了需要Android的基础绘图知识外,还需要一定的数学计算的功底,比如基本的几何图形的点的计算你要清楚。怎么让绘制的角度变化起来呢?这个问题问的好。这个就牵扯出我们动画的一个关键类,TypeEvaluator,这个接口可以让我们只需要指定边界值,就可以根据动画执行的时长,来动态计算出当前的渐变值。
private inner class AnimationEvaluator : TypeEvaluator<Float> {
override fun evaluate(fraction: Float, startValue: Float, endValue: Float): Float {
return if (endValue > startValue) {
startValue + fraction * (endValue - startValue)
} else {
startValue - fraction * (startValue - endValue)
}
}
}
百分比渐变的固定写法,是不是应该记个笔记,方便以后CP?那么现在我们条件都成熟了,只需要将初始角度的百分比改变一下,我们写一个改变角度百分比的方法。
fun setPercentRate(rate: Float) {
if (animator == null) {
animator = ValueAnimator.ofObject(
AnimationEvaluator(),
percentRate,
rate
)
}
animator?.addUpdateListener { animation: ValueAnimator ->
val value = animation.animatedValue as Float
angle =
if (progressType == PROGRESS_TYPE_CIRCLE || progressType == PROGRESS_TYPE_CIRCLE_REVERSE) {
(value * 360).toInt()
} else if (progressType == PROGRESS_TYPE_SEMICIRCLE || progressType == PROGRESS_TYPE_SEMICIRCLE_REVERSE) {
(value * 180).toInt()
} else {
0
}
percentRate = value
invalidate()
}
animator?.interpolator = LinearInterpolator()
animator?.setDuration(animationTime.toLong())?.start()
animator?.addListener(object : Animator.AnimatorListener {
override fun onAnimationStart(animation: Animator) {}
override fun onAnimationEnd(animation: Animator) {
percentRate = rate
listener?.onComplete()
}
override fun onAnimationCancel(animation: Animator) {}
override fun onAnimationRepeat(animation: Animator) {}
})
}
这里牵扯到了Animator。有start就一定不要忘了异常中断的情况,我们可以写一个reset的方法来中断动画执行,恢复到初始状态。
fun reset() {
percentRate = 0f
animator?.cancel()
}
如果你不reset,想连续执行动画,则两次调用的时间间隔一定要大于动画时长,否则就应该先取消动画。
涉及到的Android绘图知识点
我们归纳一下完成这个自定义View需要具备的知识点。
- 基本图形的绘制,这里主要是扇形
- 测量和画板的平移变换
- 自定义属性的定义和解析
- Animator和动画估值器TypeEvaluator的使用
思路和灵感来自于系统化的基础知识
这个控件其实并不难,主要就是动态配置一些参数,然后在计算上稍微复杂一些,需要一些数学的功底。那么你为什么没有思路呢?你没有思路最可能的原因主要有以下几个可能。
- 自定义View的基础绘图API不熟悉
- 动画估值器使用不熟悉
- 对自定义View的基本流程不熟悉
- 看的自定义View的源码不够多
- 自定义View基础知识没有系统学习,导致是一些零零碎碎的知识片段
- 数学功底不扎实
我觉得往往不是你不会,这些基础知识点你可能都看到过很多次,但是一到自己写就没有思路了。思路和灵感来自于大量源码的阅读和大量的实践。大前提就是你得先把自定义View的这些知识点系统学习一下,先保证都见过,然后才是将它们融会贯通,用的时候信手拈来。







































































































































































































































 可以看到在该场景下枚举类没有被优化。
可以看到在该场景下枚举类没有被优化。














 增加后,可在xml文件中查看反转后的效果 2. 新增value-ar文件夹
增加后,可在xml文件中查看反转后的效果 2. 新增value-ar文件夹

 把values/strings.xml文件复制到values-ar文件中,逐条翻译即可。
把values/strings.xml文件复制到values-ar文件中,逐条翻译即可。






 此时会影响hint的展示:在勾选时,hint的结束字符在右侧;不勾选时,hint的结束字符在左侧。
此时会影响hint的展示:在勾选时,hint的结束字符在右侧;不勾选时,hint的结束字符在左侧。