
iOS开发性能监控
App 的性能问题虽然不会导致 App不可用,但依然会影响到用户体验。如果这个性能问题不断累积,达到临界点以后,问题就会爆发出来。这时,影响到的就不仅仅是用户了,还有负责App开发的你。
线下性能监控
其中线下监控使用的还是Instruments,Instruments功能很强大,下图是Instruments的各种性能检测工具。
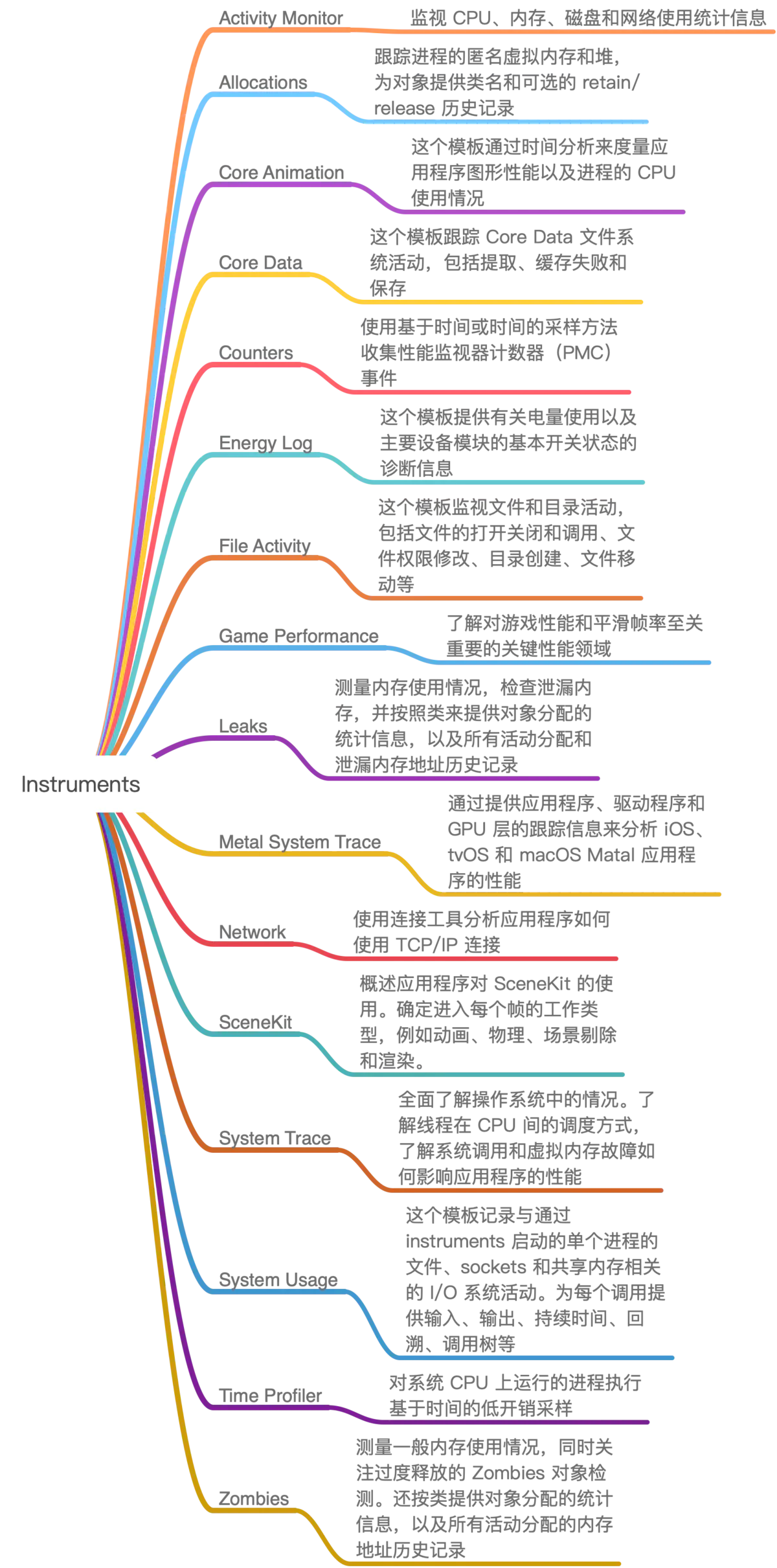
最新版本的Instruments 10还有以下两大优势:
1.Instruments基于os_signpost 架构,可以支持所有平台。
2.Instruments由于标准界面(Standard UI)和分析核心(Analysis Core)技术,使得我们可以非常方便地进行自定义性能监测工具的开发。当你想要给Instruments内置的工具换个交互界面,或者新创建一个工具的时候,都可以通过自定义工具这个功能来实现。
从整体架构来看,Instruments 包括Standard UI 和 Analysis Core 两个组件,它的所有工具都是基于这两个组件开发的。而且,你如果要开发自定义的性能分析工具的话,完全基于这两个组件就可以实现。
开发一款自定义Instruments工具,主要包括以下这几个步骤:
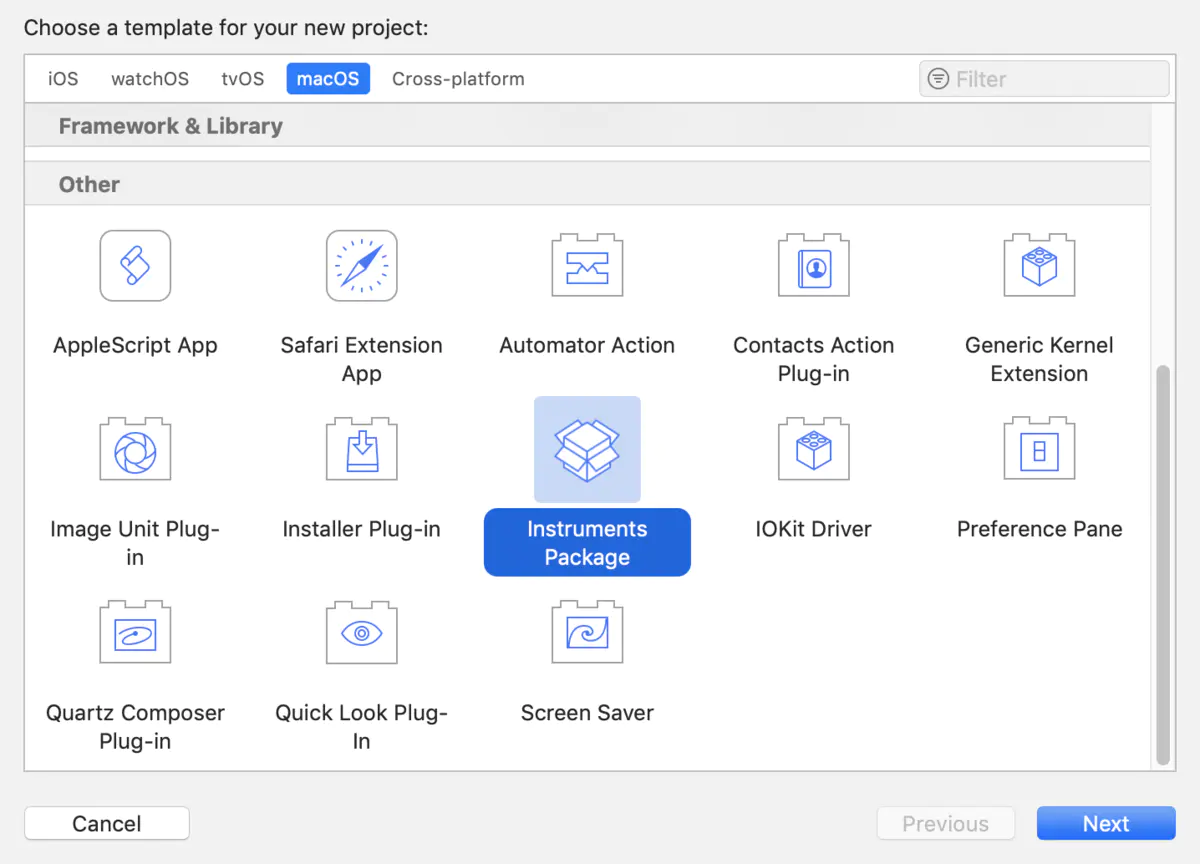
1.在Xcode中,点击File > New > Project;
2.在弹出的Project模板选择界面,将其设置为macOS;
3.选择 Instruments Package,点击后即可开始自定义工具的开发了。如下图所示。
经过上面的三步之后,会在新创建的工程里面生成一个.instrpkg 文件,接下来的开发过程主要就是对这个文件的配置工作了。这些配置工作中最主要的是要完成Standard UI 和 Analysis Core 的配置。
上面这些内容,就是你在开发一个自定义Instruments工具时,需要完成的编码工作了。可以看到,Instruments 10版本的自定义工具开发还是比较简单的。与此同时,苹果公司还提供了大量的代码片段,帮助你进行个性化的配置。你可以点击这个链接,查看官方指南中的详细教程。
再说一下,线上性能监控
对于线上性能监控,我们需要先明白两个原则:
1、监控代码不要侵入到业务代码中;
2、采用性能消耗最小的监控方案。
接下来我们从CPU使用率、FPS的帧率和内存这三个方面,说一下线上性能监控
CPU使用率的线上监控方法
App作为进程运行起来后会有多个线程,每个线程对CPU 的使用率不同。各个线程对CPU使用率的总和,就是当前App对CPU 的使用率。明白了这一点以后,我们也就摸清楚了对CPU使用率进行线上监控的思路。
在iOS系统中,你可以在 usr/include/mach/thread_info.h 里看到线程基本信息的结构体,其中的cpu_usage 就是 CPU使用率。结构体的完整代码如下所示:
struct thread_basic_info {
time_value_t user_time; // 用户运行时长
time_value_t system_time; // 系统运行时长
integer_t cpu_usage; // CPU 使用率
policy_t policy; // 调度策略
integer_t run_state; // 运行状态
integer_t flags; // 各种标记
integer_t suspend_count; // 暂停线程的计数
integer_t sleep_time; // 休眠的时间
};因为每个线程都会有这个 thread_basic_info 结构体,所以接下来的事情就好办了,你只需要定时(比如,将定时间隔设置为2s)去遍历每个线程,累加每个线程的 cpu_usage 字段的值,就能够得到当前App所在进程的 CPU 使用率了。实现代码如下:
- (integer_t)cpuUsage {
thread_act_array_t threads; //int 组成的数组比如 thread[1] = 5635
mach_msg_type_number_t threadCount = 0; //mach_msg_type_number_t 是 int 类型
const task_t thisTask = mach_task_self();
//根据当前 task 获取所有线程
kern_return_t kr = task_threads(thisTask, &threads, &threadCount);
if (kr != KERN_SUCCESS) {
return 0;
}
integer_t cpuUsage = 0;
// 遍历所有线程
for (int i = 0; i < threadCount; i++) {
thread_info_data_t threadInfo;
thread_basic_info_t threadBaseInfo;
mach_msg_type_number_t threadInfoCount = THREAD_INFO_MAX;
if (thread_info((thread_act_t)threads[i], THREAD_BASIC_INFO, (thread_info_t)threadInfo, &threadInfoCount) == KERN_SUCCESS) {
// 获取 CPU 使用率
threadBaseInfo = (thread_basic_info_t)threadInfo;
if (!(threadBaseInfo->flags & TH_FLAGS_IDLE)) {
cpuUsage += threadBaseInfo->cpu_usage;
}
}
}
assert(vm_deallocate(mach_task_self(), (vm_address_t)threads, threadCount * sizeof(thread_t)) == KERN_SUCCESS);
return cpuUsage;
}在上面这段代码中,task_threads 方法能够取到当前进程中的线程总数 threadCount 和所有线程的数组 threads。
接下来,我们就可以通过遍历这个数组来获取单个线程的基本信息。其中,线程基本信息的结构体是 thread_basic_info_t,这个结构体里就包含了我们需要的 CPU 使用率的字段 cpu_usage。然后,我们累加这个字段就能够获取到当前的整体 CPU 使用率。
接下来我们说说关于FPS的监控
FPS 线上监控方法
FPS 是指图像连续在显示设备上出现的频率。FPS低,表示App不够流畅,还需要进行优化。
但是,和前面对CPU使用率和内存使用量的监控不同,iOS系统中没有一个专门的结构体,用来记录与FPS相关的数据。但是,对FPS的监控也可以比较简单的实现:通过注册 CADisplayLink 得到屏幕的同步刷新率,记录每次刷新时间,然后就可以得到 FPS。具体的实现代码如下:
- (void)startMonitoring {
if (_link) {
[_link removeFromRunLoop:[NSRunLoop mainRunLoop] forMode:NSRunLoopCommonModes];
[_link invalidate];
_link = nil;
}
_link = [CADisplayLink displayLinkWithTarget:self selector:@selector(fpsDisplayLinkAction:)];
[_link addToRunLoop:[NSRunLoop mainRunLoop] forMode:NSRunLoopCommonModes];
}
- (void)fpsDisplayLinkAction:(CADisplayLink *)link {
if (_lastTime == 0) {
_lastTime = link.timestamp;
return;
}
self.count++;
NSTimeInterval delta = link.timestamp - _lastTime;
if (delta < 1) return;
_lastTime = link.timestamp;
_fps = _count / delta;
NSLog(@"count = %d, delta = %f,_lastTime = %f, _fps = %.0f",_count, delta, _lastTime, _fps);
self.count = 0;
}
内存使用量的线上监控方法
通常情况下,我们在获取 iOS 应用内存使用量时,都是使用task_basic_info 里的 resident_size 字段信息。但是,我们发现这样获得的内存使用量和 Instruments 里看到的相差很大。后来,在 2018 WWDC Session 416 iOS Memory Deep Dive中,苹果公司介绍说 phys_footprint 才是实际使用的物理内存。
内存信息存在 task_info.h (完整路径 usr/include/mach/task.info.h)文件的 task_vm_info 结构体中,其中phys_footprint 就是物理内存的使用,而不是驻留内存 resident_size。结构体里和内存相关的代码如下:
struct task_vm_info {
mach_vm_size_t virtual_size; // 虚拟内存大小
integer_t region_count; // 内存区域的数量
integer_t page_size;
mach_vm_size_t resident_size; // 驻留内存大小
mach_vm_size_t resident_size_peak; // 驻留内存峰值
...
/* added for rev1 */
mach_vm_size_t phys_footprint; // 物理内存
...我们只要从这个结构体里取出phys_footprint 字段的值,就能够监控到实际物理内存的使用情况了。具体实现代码如下:
- (unsigned long)memoryUsage {
task_vm_info_data_t vmInfo;
mach_msg_type_number_t count = TASK_VM_INFO_COUNT;
kern_return_t result = task_info(mach_task_self(), TASK_VM_INFO, (task_info_t) &vmInfo, &count);
if (result != KERN_SUCCESS)
return 0;
return vmInfo.phys_footprint;
}从以上三个线上性能监控方案可以看出,它们的代码和业务逻辑是完全解耦的,监控时基本都是直接获取系统本身提供的数据,没有额外的计算量,因此对 App 本身的性能影响也非常小,满足了我们要考虑的两个原则。
你可以点击这个链接,查看具体demo,欢迎大家点赞。
链接:https://www.jianshu.com/p/cc02a1e1e019
